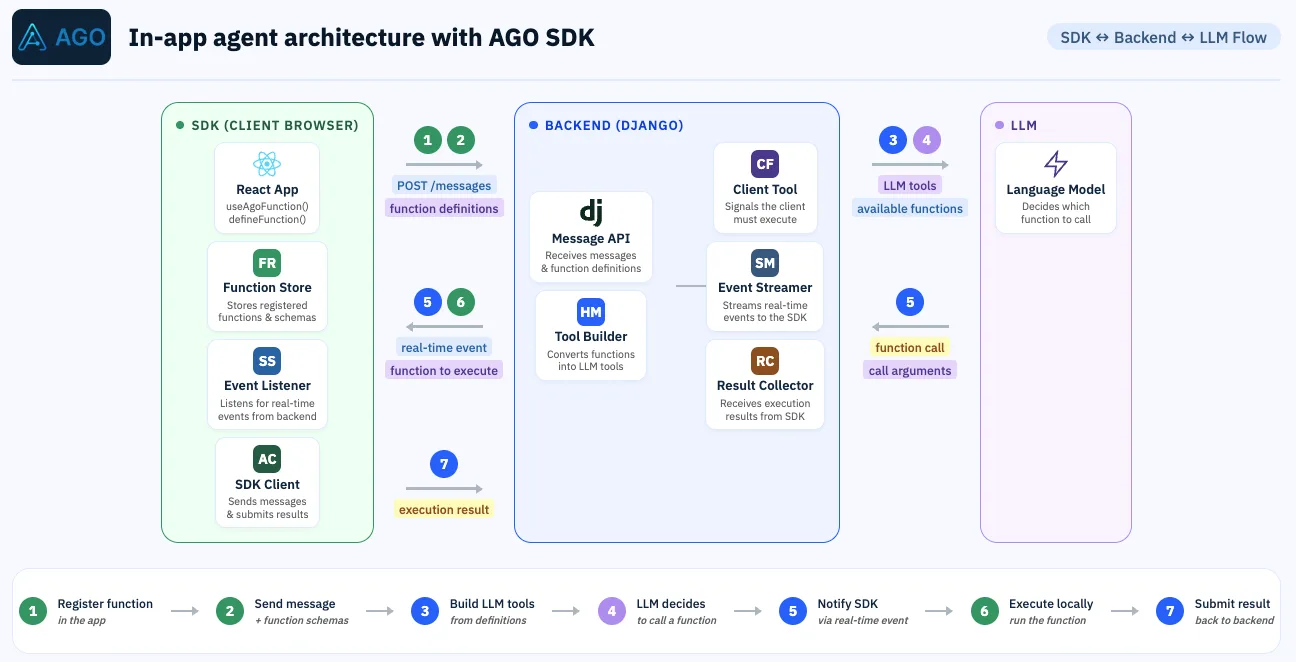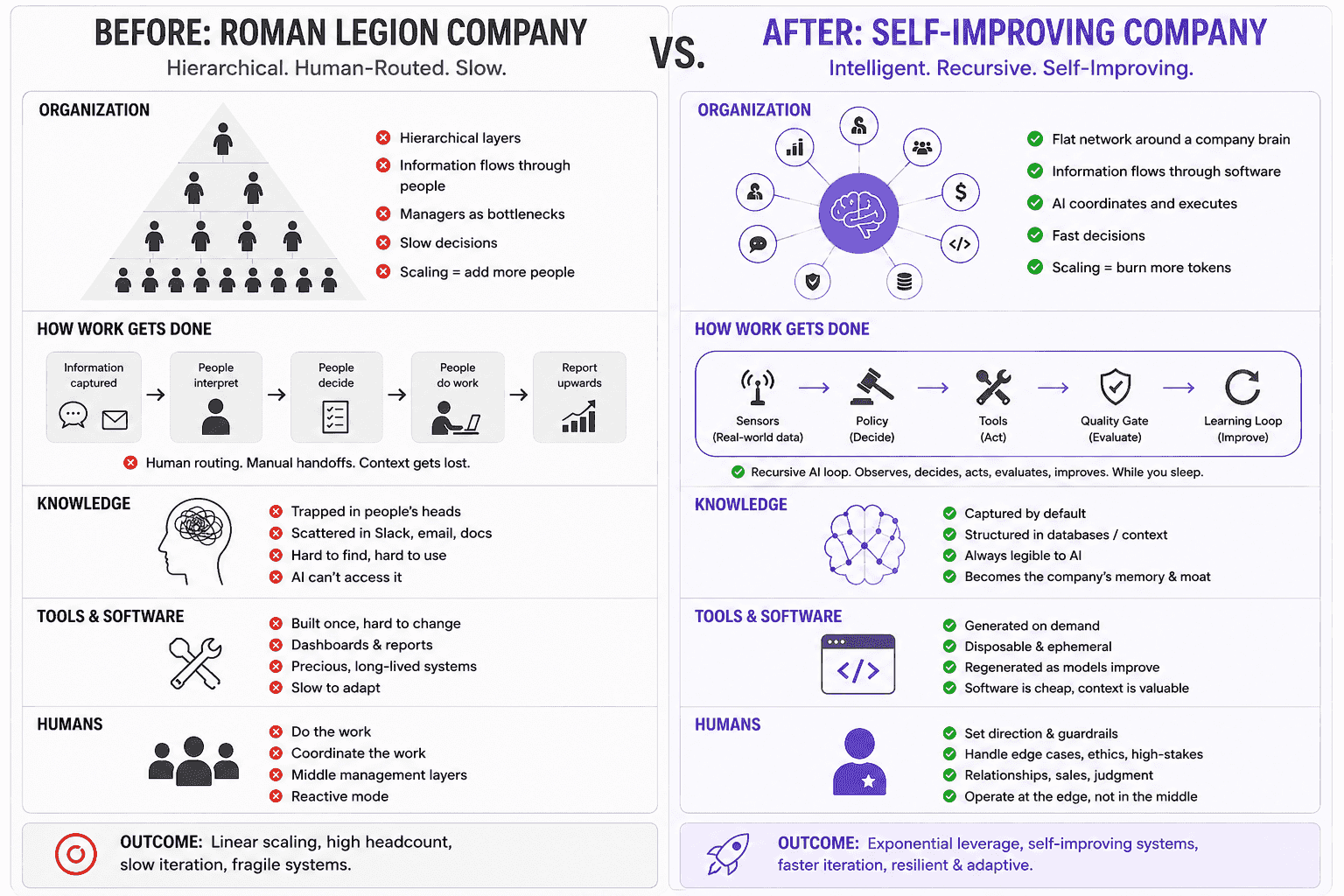
There is a talk from YC that is really good. Tom shared that company can be seen as a set of recursive self-improving AI loops. Each loop has a sensor layer, a policy layer, a tool layer, a quality gate, and a learning mechanism. If you can wire those five pieces together inside a part of your business, that part starts improving on its own. While you sleep.
I want to make a point in this post that is a little selfish but I think it is also true. If you deploy AGO for your customer operations, you do not have to design that loop yourself. You already have one. AGO is the loop.
To make the contrast obvious, here is what most teams actually ship today. A linear chatbot stack. Signal goes in, an answer comes out, and the next day every learning evaporates.
What most teams ship instead
A one way pipeline. Signal flows in, an answer flows out, nothing learns.
With AGO the picture changes. The conversation still happens between a customer and an agent, but every exchange writes into something we call your company brain. It is the shared memory the AI can actually see. Documents, policies, past conversations, quality signals, learnings. Every new conversation reads from it before answering, and writes back into it once it is done.
With AGO, every conversation feeds the company brain
AGO handles the conversation. Then a learning step writes back into the company brain so the next conversation starts smarter.
The five layers, mapped to AGO
Let me walk through the five pieces and show where each one already lives in AGO today.
Layer 01. Data sensors
The sensor layer is the part that captures signal from the outside world. For a customer operations team that signal is the conversations themselves. Every chat. Every email reply. Every escalation. Every reopen.
AGO records every one of these interactions across every channel you have plugged in. We treat conversations as a first class data type, not as ticket exhaust. That matters because conversations are where customers actually tell you what is broken in your product, what is missing in your docs, what is unclear in your pricing page, what is confusing about your refund flow. If you do not capture them properly, your AI cannot see them and your company cannot learn from them.
But conversations are not the only signal. AGO also captures what docs your users are reading, the tickets they create, and which tool has been used with which arguments. Each of these tells you something the conversation alone might miss. A doc that is opened a hundred times a day but never resolves a question. A category of ticket that spikes after a new release. A tool that gets called with the same broken arguments every time a specific intent comes up. All of it goes into the same sensor layer.
Layer 02. Policy layer
The policy layer is the rules of engagement with your customer. What can the AI say. What can it promise. When does it need to escalate. What does it have to log. What requires a human signature.
Layer 03. Tool layer
This is the interesting one because we run two sets of tools, not one.
The first set is the customer facing tools. The agent can check an order, issue a refund, reschedule a delivery, update a shipping address, generate a return label, change a subscription plan. These are the deterministic actions your customer was going to call you about. With AGO they happen inside the conversation, end to end, without a human having to copy and paste between tabs.
The second set is the internal tools. The same agent infrastructure can query your business documentation, propose edits to your help center, draft a new policy, open a pull request on your knowledge base, surface drift between what you tell customers and what your code actually does. This is the part most teams miss when they think about customer support automation. The loop is not just about resolving tickets. It is about feeding everything the agent learned back into the business itself.
Layer 04. Quality gates
A self-improving loop without quality gates is just a feedback loop that drifts.
AGO runs quality checks from four angles, so no single signal can quietly mislead the loop:
- Customer evaluation. Thumbs, ratings, and post conversation surveys, mapped back to the actual exchange that produced them.
- Admin feedback. Your team can flag a conversation as wrong, missing a step, or off policy, and that judgment carries more weight than any automated score.
- Doc evaluations. Every page in your knowledge base gets scored against the conversations that referenced it, so stale or contradictory docs surface.
- LLM as judge. An independent model reviews each conversation against your policies and known good answers, catching drift the customer never complained about.
Together these four produce structured signals. Not vague vibes. Concrete spots where the loop is leaking quality. That signal is what the learning agent chews on next.
Layer 05. Learning agent
This is the layer that closes the loop.
We run a learning agent on top of the quality signal. It looks at the gaps the quality gates expose, asks why they happened, and proposes concrete changes. Sometimes the answer is to update a documentation page. Sometimes it is to update the prompt. Sometimes it is to tighten a policy. Sometimes it is to flag a product bug that no number of doc edits will fix.
The agent does not push changes blindly. It surfaces proposals. A human approves what ships. But the heavy work of noticing, diagnosing, and drafting the change is no longer on a person. It happens overnight. By the time someone arrives the next morning, there is a queue of well formed suggestions sitting on the desk.
Why this matters for customer operations specifically
Customer operations is the easiest part of a company to wrap in a self-improving loop. The signal is dense. The conversations come in by the thousand. The outcomes are clean and measurable. Resolved or not. Reopened or not. Satisfied or not.
That is why I think customer operations is the first function in most companies where a true self-improving loop becomes possible. And once you have it there, you start seeing the same pattern in other functions. Product analytics. Sales calls. Internal ops. The shape of the loop does not change. The sensors change. The tools change. The policies change. The pattern is the same.
But you have to start somewhere. And starting with customer operations is the rare case where the loop pays for itself in week one, because every resolved ticket is money you would have spent on a human agent. The improvement layer just compounds on top of an already positive return.
What you actually have to do
If you deploy AGO, the loop is already wired. You do not have to design the sensor schema. You do not have to write a policy engine. You do not have to assemble the tool set. You do not have to build an eval harness. You do not have to spin up a learning agent.
You do have to do the part that is yours. Tell us your policies. Connect your systems so the tools can act. Approve the proposals the learning agent surfaces. Decide which gaps are worth fixing this week.
That is the work. Everything else loops on its own.
If you want to see this running in your environment, get in touch. The conversation we have with you on day one is itself a signal in the loop. It always is.