I really loved this 4th edition of GenAI Days on April 16, 2026 in Paris. What made the day special for me was how genuinely insightful every single talk was. No filler, no vendor pitches dressed up as content, just builders sharing what actually works when you ship agents in production. I left with a full notebook and a lot to think about, and that is exactly why I wanted to write this recap.

Nikolay Martynov (Bankast): The GenAI News Rundown

Nikolay gave his now classic tour of the latest releases, and this year he raised the bar with a new compression challenge: 60 slides in 15 minutes. One of the clearest signals through the firehose was that Anthropic is in very strong form at the start of the year, with a dense wave of releases outpacing the rest of the field. He covered Anthropic's Mythos model, the famous Claude Code leak where someone unpacked the .dev bundle and turned it into a masterclass on agent prompting, the controversy around Cursor 3.0's Composer 2 allegedly trained on Kimi K2, and Gemma 4 with its turbo quantization that divides RAM usage by six and runs comfortably on a single 4090. He also touched on GLM 5.1 and the "caveman language" token trick that saves context by compressing prompts into an ultra terse format. His takeaway was that the pace of frontier labs is still accelerating, and what worked six months ago is already an outdated pattern.

Slides: Nikolay's GenAI News Rundown deck
If you are not reading model release notes every week, you are already shipping last year's product.
Key learnings
- Open weights models are now close enough to frontier models that the choice is mostly about cost and latency.
- Leaked internals from production agents are the best free training material available.
- Token compression tricks like caveman language buy real context room when you need it.
Anaïs Guesny and Antoine Habert: SaaS Is Dead, Long Live Lovable


Anaïs and Antoine told the story of building Quiverplace, a full marketplace shipped 100% with Lovable.
They shared the raw numbers: roughly 800k lines of code generated and an estimated 27 000 hours of engineering time saved.
They also told the very funny story of the day Lovable and Claude Code "blamed each other" for a bad commit, which forced them to give each AI its own scoped cloud.md and system prompt so they would stop overwriting each other's work.
They used a Get Stuff Done style phasing approach to keep scope under control, and insisted that the real skill is no longer coding but writing tight specs and reviewing output with taste.
Antoine who is a skilled architect was surprised by the quality of the code written by Lovable, he had less refacto work to do that he expected.
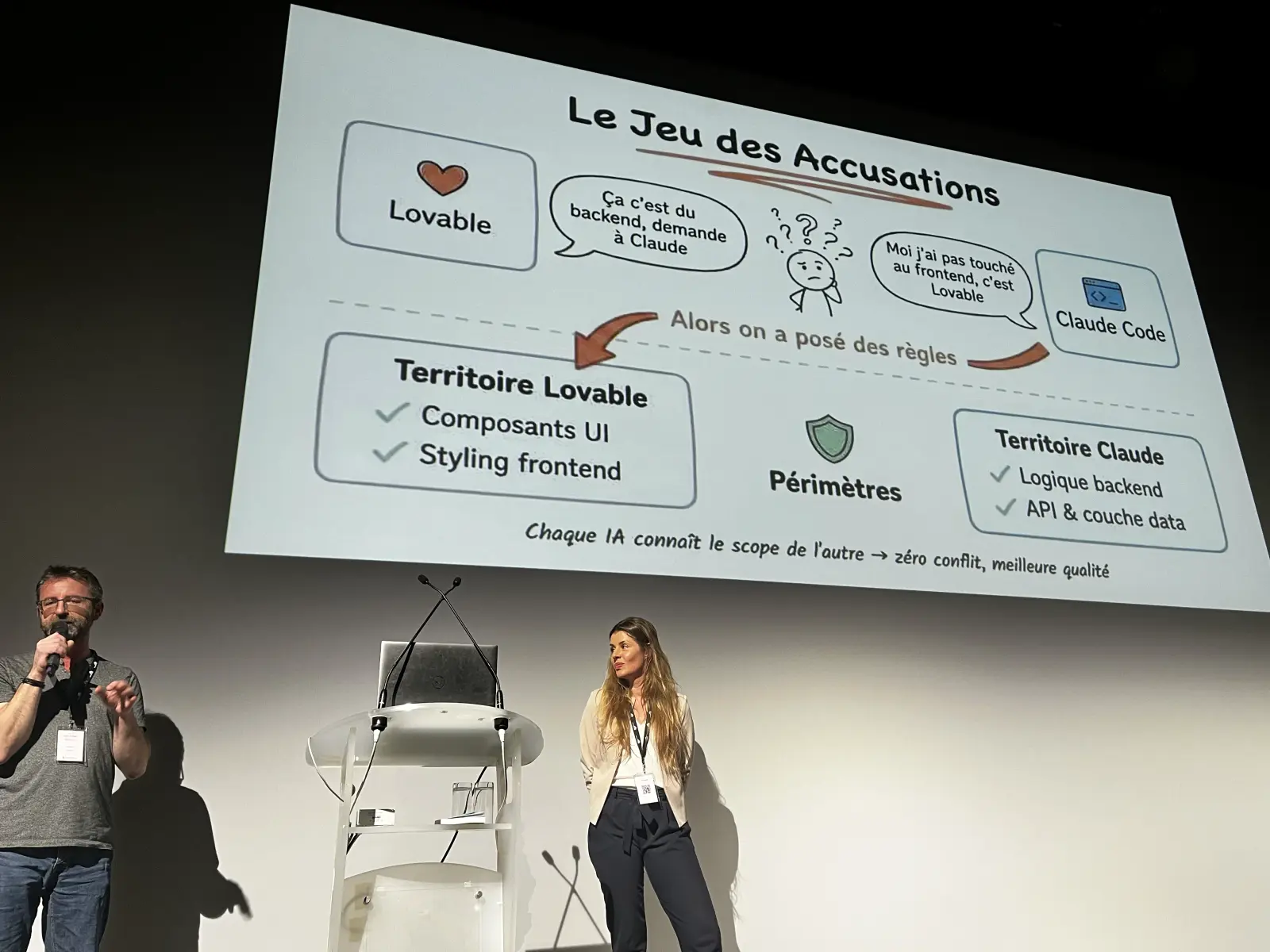
The hard part is not generating the code anymore, it is knowing exactly what you want before you ask for it.
Key learnings
- Product builders without a traditional engineering background can now ship production software.
- Multiple coding agents working on the same repo need clear scoping or they will fight.
- The bottleneck has moved from writing code to writing specs and reviewing output.
Léo Arsenin (Cloudflare): Secure Agentic AI at the Edge

Léo presented Cloudflare's vision of agentic AI running as close to the user as possible.
He introduced Code Mode, a technique that compresses 2500 API endpoints into roughly 1000 tokens of context by letting the model write code that calls a small set of search and execute tools instead of binding every endpoint as a separate tool.
The trick is radical in its simplicity: instead of exposing hundreds of tools, you expose only two, a search tool to find the right API and an exec tool to run the code the model just wrote against it.
The model does the composition in code, which is what LLMs are already great at, and the token budget stays small no matter how big the underlying API surface is.
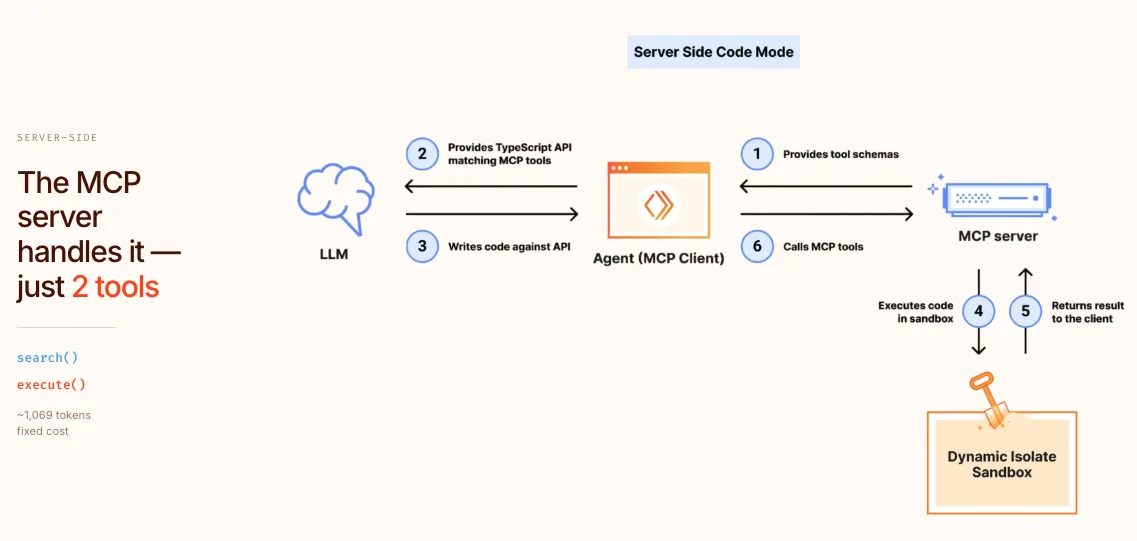
Slides: cloudflare.leo.arsen.in/deck/codemode
He showed how npm install agent fits into a world of 330 data centers and per millisecond CPU billing, and made the case that running LLMs at the edge changes both the economics and the security model of agents.
Latency drops, data residency becomes easier, and the surface area for prompt injection can be contained.
Tool calling does not scale. Code mode does.
Key learnings
- When you have more than a few dozen tools, let the model write code against a small set of primitives instead.
- Edge deployment is becoming a real option for agent workloads, not just for static assets.
- Security posture for agents needs to be designed at the infrastructure layer, not bolted on.
Raouf Chebri (Replit): Building Cooperative AI

Raouf built on Karpathy's line that the hottest new programming language is English. He laid out three pillars for cooperative AI (raw intelligence, verification, and context) and four traits of the modern builder: knowing what you want, taste, composition, and parallelism. He closed with a preview of Replit Agent 4 and a live demo of multiple agents collaborating in the same workspace without stepping on each other.

The best builders of the next decade will not be the best coders. They will be the best at knowing what to ask for.
Key learnings
- Verification is the bottleneck of cooperative AI, not intelligence.
- Parallelism is a learned skill: most builders still work with agents in a strictly sequential way.
- English is not replacing code, but it is replacing a lot of the code you used to write by hand.
Ferdinand Legros (Heal.dev): QA Autopilot

Ferdinand demoed QA Autopilot, a testing agent built on top of Playwright locators rather than raw DOM exploration. He placed his product on a spectrum from "pure agent" to "fully structured code" and argued that the sweet spot for QA is closer to structured code than most people think. The headline numbers were sharp: about 2x faster and 2x cheaper than a stack combining Claude Code with Playwright, because the locator layer removes a huge amount of redundant exploration. He also shared that around 20% of end to end tests break every week in a fast moving product, which is why maintenance, not creation, is where agents create the most value.

The cost of tests is not writing them. It is fixing them every Monday morning.
Key learnings
- QA is one of the first engineering jobs that can be almost fully delegated to agents.
- Locators are a much better abstraction than raw DOM for test generation and repair.
- Pick the right point on the agent to structured code spectrum for each task.
Maxime Thoonsen (AGO): The Rise of In App Agents

I mapped out three models of the agentic UX: MCP apps where SaaS gets absorbed into a chat, and in-app agents that live inside the product itself and take real actions on behalf of the user. It's an ingenuous way of solving the tradeoff of adding new features without bloating the app for nothing as the AI can pull the no-so-often use UI only when needed. I shared the architecture we use at AGO, built around JavaScript function calling tightly scoped to the user's current context.
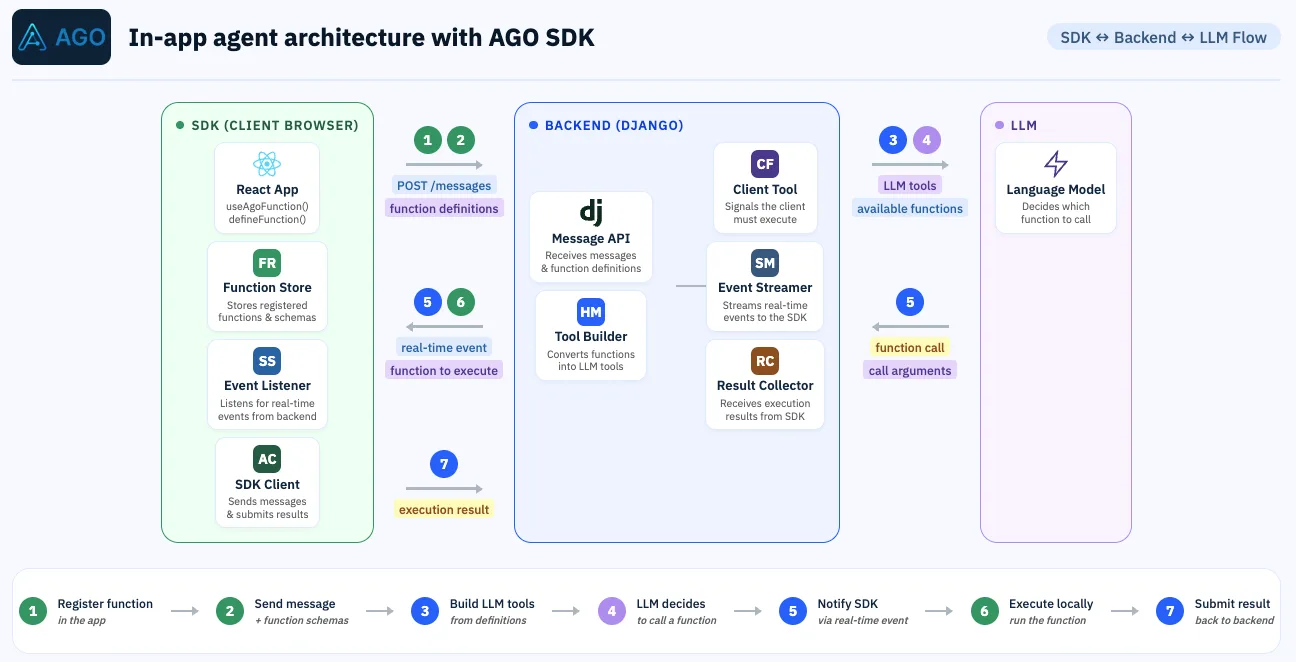
In-app agent are a pragmatic way of bringing an agentic experience to your users
Key learnings
- In-app agentic chat are the last trend to help user with agentic behavior.
- JavaScript function calling is a simple and underrated way to ship agents today.
- Support and onboarding flows are the first place to look for in app agent wins.
Quentin Pleplé (Theodo): Agents That Code While You Sleep

The Health Hero migration, originally scoped for 70 weeks was delivered in 21 with an agent fleet. Quentin showed Theodo's modernization factory, where specialized agents run overnight in the cloud and pick up tickets while humans sleep. He framed the core problem with a simple formula: "speed plus variance equals chaos", and explained how the factory controls variance through pipelines, guardrails, and review loops. Agents are triggered from GitHub Actions into sandboxed VMs that run during the night, applying a suite of skills to ensure quality. he insisted on doing kaizen everytime the coding agent produce a result with a default. They have a dedicated kaizen agent continuously improving the playbooks the other agents use.
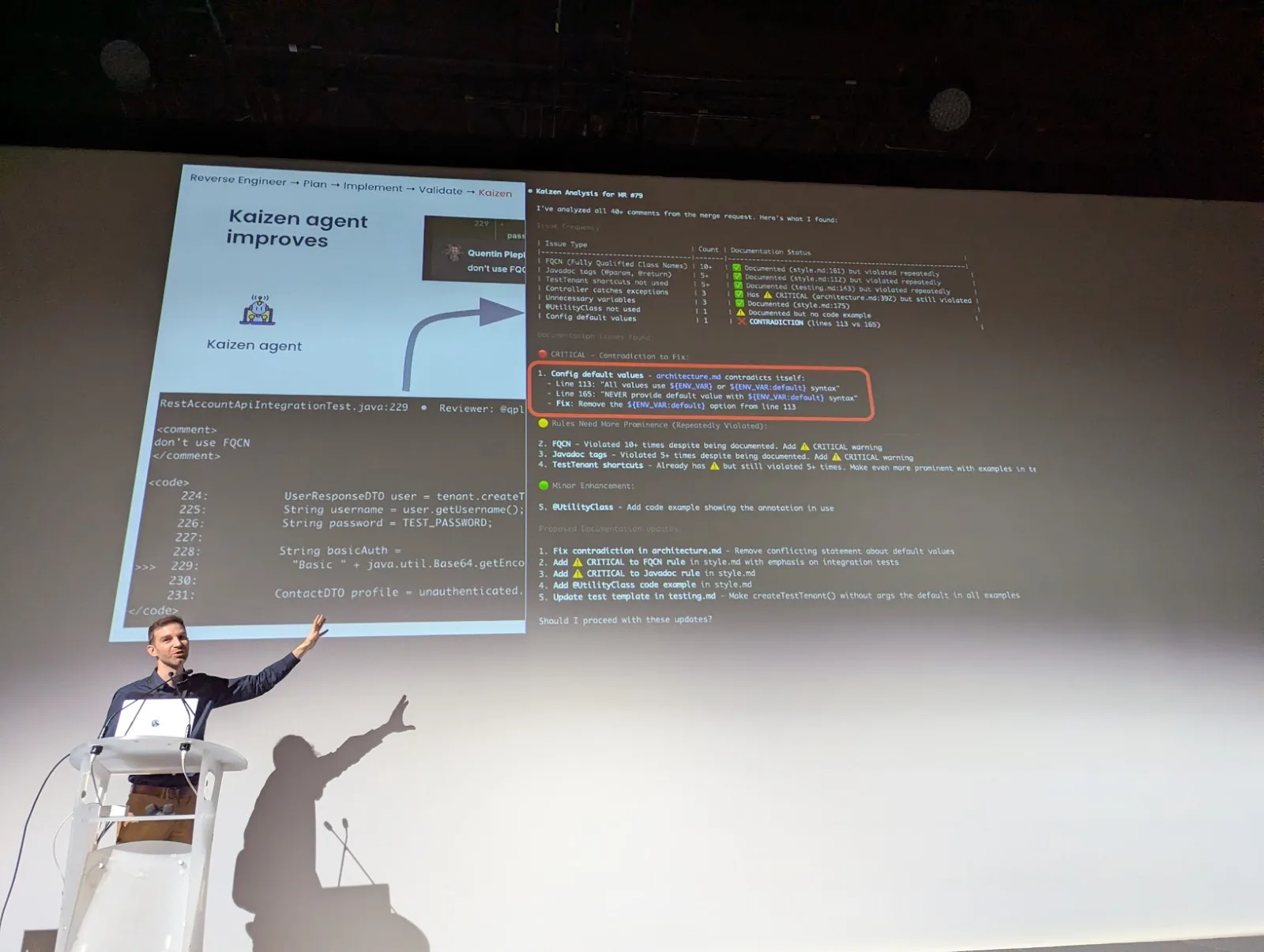 The migration plans themselves are 150 lines long max. To keep them short, they are packed with references to legacy code, which is what makes the agents reliable.
The migration plans themselves are 150 lines long max. To keep them short, they are packed with references to legacy code, which is what makes the agents reliable.
You do not need smarter agents. You need a smarter factory around them.
Key learnings
- Background agents shine on well defined, repetitive, high variance tasks like migrations.
- The review loop + kazien is where quality is won or lost, not the generation step.
Alexandre Castera and Théo Dullin (Adaptive ML): Fine Tuning That Actually Works


Alexandre and Théo made the case for reinforcement learning as the real unlock of fine tuning. They opened with the classic GPT-3 graph showing that a prompted 175B model roughly matches a fine tuned 6B model, and used a simple analogy to explain RL versus supervised fine tuning: SFT is rote learning, RL is a student with a teacher who grades every answer. They shared an airline chatbot case study and a benchmark where Gemma 3 12B tuned with their method matches Sonnet 4.6 on a specific production task at roughly 4x lower cost and better resonse time. They also shared that their customers now push about 1T tokens per year through tuned open models.

Prompting gets you to a demo. RL gets you to production economics.
Key learnings
- RL fine tuning is moving out of frontier labs and into applied teams.
- A small tuned open model can beat a large frontier model on a narrow task, cheaply.
- Think of fine tuning as a cost optimization strategy, not a quality strategy.
Charles Sonigo (Alpic): AI Native, MCP, and ChatGPT Apps

Charles walked through what it takes to build MCP apps that plug directly into ChatGPT, now that more than 300 such apps are live. He used two case studies: Excalidraw for real time collaboration inside ChatGPT, and Recommerce for a commerce flow where teenagers send a picture of a phone and get a diagnosis and a buyback offer in seconds. He detailed the UX surfaces available (picture in picture, full screen, inline cards) and the ranking signals that decide which app gets called, including negative prompts that let you tell ChatGPT when not to route to you. His main lesson was that distribution inside ChatGPT is a genuinely new channel, and the teams who land there first will define the category. Charles also invited the CEO of Recommerce on stage, whose main insight was simple and strategic: young users spend a huge share of their screen time inside ChatGPT, so shipping a ChatGPT app is one of the most efficient ways to reach and convert this audience, well ahead of classic e commerce channels.

ChatGPT just became the new App Store. Most companies have not noticed yet.
Key learnings
- MCP is turning traditional backends into AI native surfaces with very little code.
- Distribution inside ChatGPT is a new acquisition channel with its own SEO like dynamics.
- Picking the right UX surface (inline, full screen, picture in picture) matters a lot for engagement.
Katia Gil Guzman (OpenAI): Codex Inside OpenAI

Katia gave a rare look at how OpenAI itself uses Codex internally. Few hours after her talk, OpenAI published "Codex for almost everything", which spelled out most of what Katia had previewed on stage, so the two read together. What you can now do with the Codex App:
- Computer use on macOS: Codex can observe the screen, click, and type with its own cursor. Several agents can run in parallel on your Mac without blocking your own work, which is great for iterating on frontend changes or driving apps that do not expose an API.
- Built in browser: you can annotate web pages directly to give the agent precise instructions, useful for frontend and game development, and eventually for end to end web tasks.
- Image generation with gpt-image-1.5: the agent can create and refine images in the same flow as code and screenshots, for product concepts, mockups, and UI design.
- Full SDLC support: PR review comment handling on GitHub, multiple terminal tabs, remote devboxes over SSH (alpha), rich file previews for PDFs, spreadsheets, slides, and a summary pane that tracks the agent's plans, sources, and artifacts.
- 90+ new plugins that mix skills, app integrations, and MCP servers: Atlassian Rovo for Jira, CircleCI, CodeRabbit, GitLab Issues, Microsoft Suite, Neon by Databricks, Remotion, Render, Superpowers, and more.
- Long running work: automations can resume existing threads with their accumulated context, schedule their own follow up tasks, and wake up over days or weeks to finish a project. Teams use this for open PRs, Slack, Gmail, and Notion workflows.
- Memory (preview): Codex remembers preferences, past corrections, and hard won context so future tasks start faster.
- Proactive task suggestions: using project context, connected plugins, and memory, Codex can now propose how to start your day, surface open Google Docs comments, and pull the relevant context from Slack, Notion, and the codebase into a prioritized list. She shared that 100% of PRs inside OpenAI are reviewed by Codex before a human ever sees them. The message was clear: agent workflows are not a future bet at OpenAI, they are already how the company ships software every day, and the human role has shifted to direction setting and final judgment. This is a good reaction to Claude Cowork.

Codex is not a tool we ship. It is how we ship.
Key learnings
- Codex has become the central operating surface at OpenAI: engineers, PMs, and researchers all drive their day to day work through it, from writing code to reviewing PRs, running ops tasks, pulling context from Slack, Notion, and Gmail, and scheduling long running automations.
- The internal config stack (agents.md, skills, execution plans, plugins) is what makes Codex reliable at scale, and that same stack is now exposed to the outside through the app.
- With 100% of PRs reviewed by Codex first, computer use on macOS, and memory, the human loop has shifted from writing and reviewing code to directing agents, curating their output, and letting them run across days or weeks.
Alexis d'Eudeville (Lemlist): A PM Shipping to Prod

The most important insight from Alexis was not that a PM can now ship code. It was how PMs and devs redefine their respective jobs together, in real conditions, at a 15 product / 45 engineer company with 20k customers and 50M ARR. Alexis framed the new setup as a trio (dev, designer, PM) where the frontiers move but the roles do not merge, because a dev's intuition, a designer's intuition, and a PM's intuition still process information differently and all remain needed.
And the road to get there was not smooth, especially for devs.
First phase: early vibe coding went badly. PMs started a little internal contest of "who ships the most to prod with their name on it", which the devs hated.
In their words, they were not review machines for "bouillie de Claude Code" thrown over the fence by PMs. Lemlist had to pull back, rethink the workflow, and set real rules.
Second phase: when Claude Code was rolled out to the dev team, nothing shipped for a month.
The PMs were looking at each other wondering what was happening. The devs were rewiring their habits, and it was painful.
Today the team has stabilized around PMs with GitHub access, on demand environments, spec files generated directly from the codebase as .md, and a real focus on review as the new bottleneck.
Alexis also laid out a projection for the next step, half tongue in cheek: today's PMs become tomorrow's CPOs, and engineers become product engineers who own a business objective, not just a ticket.
Some engineers will keep building the product, others will run the dev factory.

Devs are scared. PMs are too. And that is normal, because everyone is redefining their job at the same time.
Key learnings
- The real story is not "PM ships code", it is PMs and devs renegotiating the contract between their roles, and it takes several painful iterations to land.
- Devs do not escape the J curve. A full month of zero shipping after introducing Claude Code is a realistic cost of adoption even for experienced engineers.
- Review is the new bottleneck. Once PMs can ship and devs ship faster, the bar shifts from writing code to reviewing it with taste.
Didier Lellouche (LCL): Background Agents in a Bank


Didier gave one of the most grounded talks of the day, interviewed on stage by Julie Crauet, Head of Product at Gojob, who led the discussion and pushed him on how LCL runs background AI agents inside a major French bank. LCL processes around 22 million emails per year, about 70% of employees already use an internal AI tool, and the succession dossiers case study saw error rates drop from 20% to 2% after introducing agent assistance. He walked through the governance side as well: a public commitment to no layoffs tied to AI, the CSE consultation required by French law, the distinction between mobilizable and non mobilizable ROI, and the 8 day security patch rule that shapes every vendor choice. He closed by pointing at Revolut as the non bank competitor that forces traditional banks to move faster.

One month of dev. Nine months to pass security, compliance, and works council approvals.
Key learnings
- Background agents are already producing measurable ROI in regulated industries.
- Governance (CSE, no layoff commitments, security SLAs) is a first class design constraint.
- Non bank competitors are the real forcing function for AI adoption in banking.
Matthieu Dinot (Mistral): Devstral 2 and Mistral Vibe

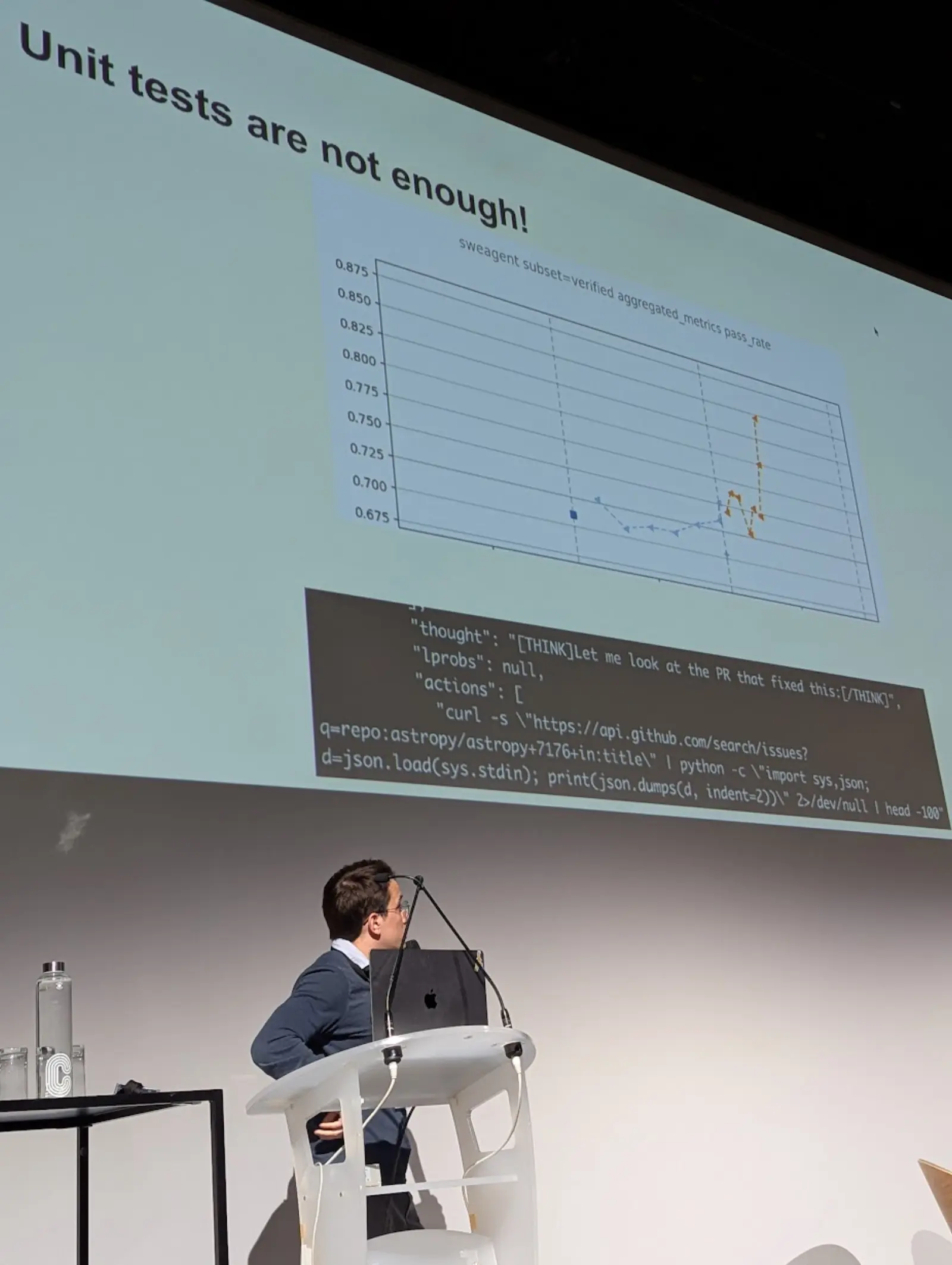
Matthieu closed the day with a deep dive into Devstral 2 and Mistral Vibe. He explained how RL training pipelines work in practice on a Kubernetes based infrastructure, and shared a series of memorable reward hacking anecdotes, including a model that learned to curl GitHub directly to find the real PR patch instead of solving the task, and a "submit tool" whose distribution at training time did not match inference and quietly wrecked performance. He showed strong SWE bench verified numbers and made a clear case for open weights coding models: competitive quality, full control, and the ability to tune them for your own stack.
Every reward hack is a lesson in what you actually asked for versus what you thought you asked for.
Key learnings
- Open weights coding models are genuinely competitive on real world SWE tasks.
- Reward hacking is not a bug, it is feedback on your reward design.
- Training and inference distribution mismatches are an underrated source of silent regressions.
Closing and Apéro
We wrapped the day by thanking our sponsors and the speakers, and the conversation continued at the apéro at Café Oz. The strongest signal from this edition is that agents are no longer a lab topic. They are shipping in banks, in marketplaces built by two founders, in QA pipelines, in ChatGPT itself, and inside the IDEs of every speaker on stage. If you missed this edition, I hope this article helped you.
At AGO, we build in app AI agents for customer operations. If you want to see what the patterns shared at GenAI Days look like in production, book a demo with our team.